Training & Testing
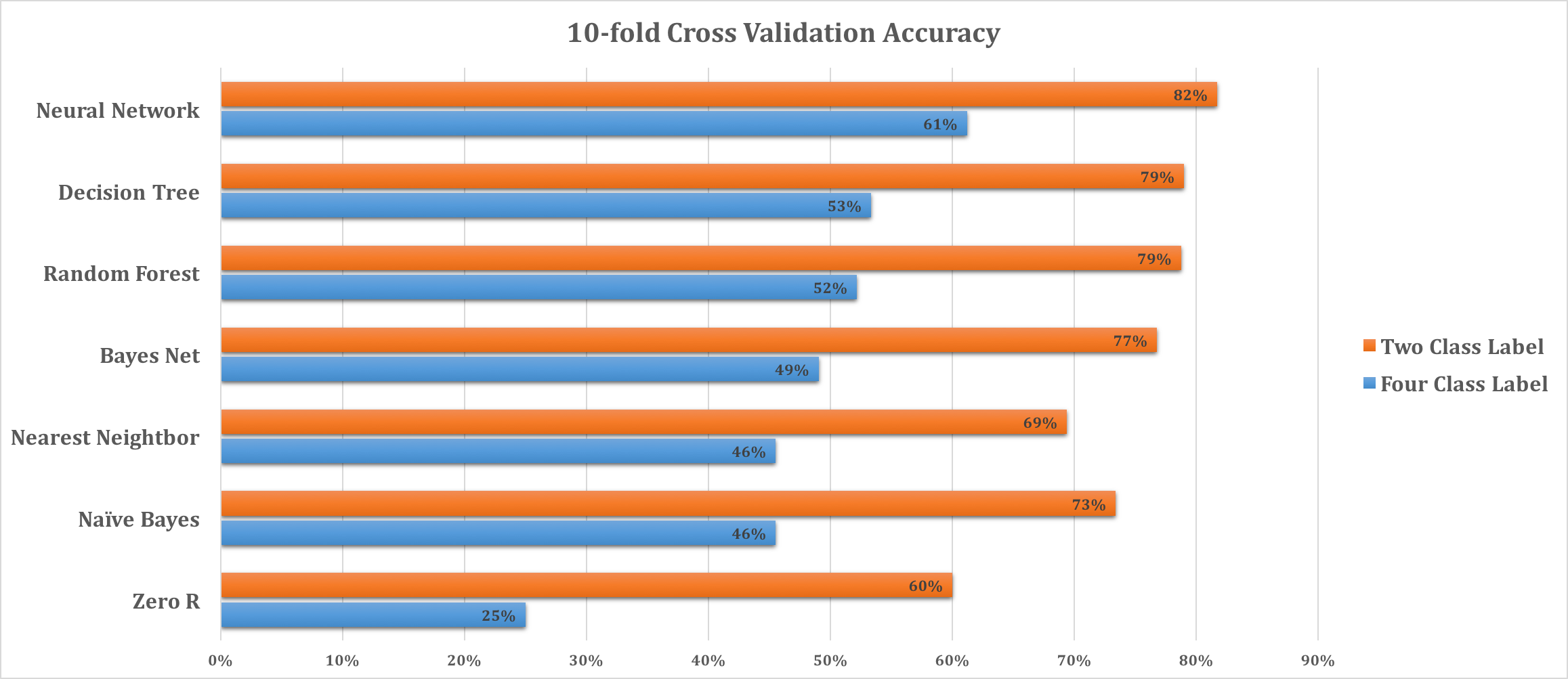
We conducted experiments on both the Quaternary Class Label and Binary Class Label dataset using a number of different models. The Quaternary Class Label, which divides movies into more usable quality classes, has the tradeoff of low prediction accuracies. However, it doesn't mean the model is necessarily less usable as the classification contains more information. In either case, the models show that the features such as award indices of director, actors and actresses as well as budget shows significant predictive power of movie quality, captured in ratings or classes in our measure.
The models that yielded considerable accuracy improvements from the base accuracy (25% and 60% as we partitioned the quality classes) for each case are included. Various parameters of the models are tuned to produce their performance. The multilayer perceptron neural network model results in the best accuracy with a slight advantage over decision tree algorithms, especially for the Four Class Label Model. We attribute this difference to the fact that the size of our data is too small for the tree models to achieve good results for the relatively big output space (quaternary vs binary). Please see a more detailed discussion about different models in the report.